contrast to heterochromatin the euchromatin is despiralized during the
interphase, it is evenly distributed in the nucleus and is more poorly stained.
The euchromatin portions are thought genetically active since it is believed
that genes are predominantly concentrated in them, while the
heterochromatin is genetically inactive. Since this problem is unclear, there is
no ground to think that heterochromatin is an inert mass devoid of any
biological importance.
image
Figure 2–46. Two differentially stained
metaphase chromosomes of barley (Hordeum
vulgaris). The dark areas indicate to the
portions of structural heterochromatin and the
light ones — to euchromatin (Courtesy of K.
Gechev, Institute of Genetic Engineering,
Kostinbrod).
Together with the long lived idea of chromatin as a smooth deoxynucleoprotein
fibres (DNP-fibre) of more or less regular super-spiralization, other models have been
launched according to which DNA is coiled in or around protein complexes localized
along the DNP-fibre. Olins and Olins (1974) have established that chromatin has a granular
structure. According to them chromatin fibres are built of bound spherical bodies of a
7—10 nm diameter (called nucleosomes) which are localized along the chromatin
fibres in a bead-like fashion. This model has aroused a great interest.
Some Deviations from the Watson and Crick Model
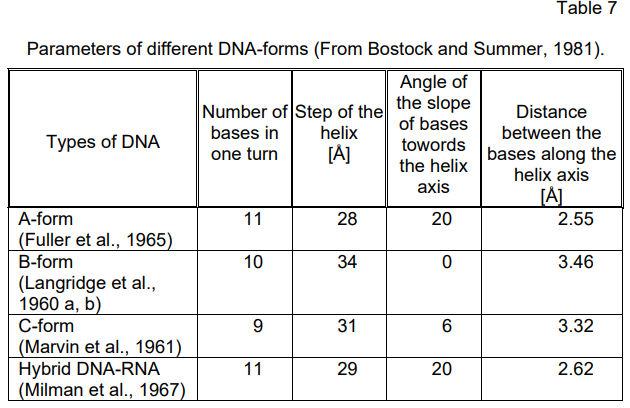
The model of the DNA double helix forwarded by Watson and Crick
corresponds to a configuration of the B-form type with a right turn. Further
investigations (Langridge et al., 1960 a, b; Marvin at al., 1961; Fuller et al.,
1965, etc.) have established that DNA can exist in three different
configurations — A-, B- and C-forms which under definite conditions can
convert into one another. The major parameters of these DNA-forms are
presented in Table 7. According to Davies and Zimmerman (1988). DNA in
chromatin assumes a special Z-conformation. Lejeune (1979) has
established a left rotation of DNA. These data are quite indicative of
nature’s capacities to create a variety of forms of existence even of such
strictly specific high-molecular compounds as DNA.
Besides, it was proved that apart from the purine/pyrimidine ratio the
ratios of the incorporated in their composition DNA-bases A : T and G : C = 1
varies to a great extent in the DNA of higher plants and animals. In many
cases A + T > G + C. Such a DNA was called the AT-type. Also the minor,