Page 102
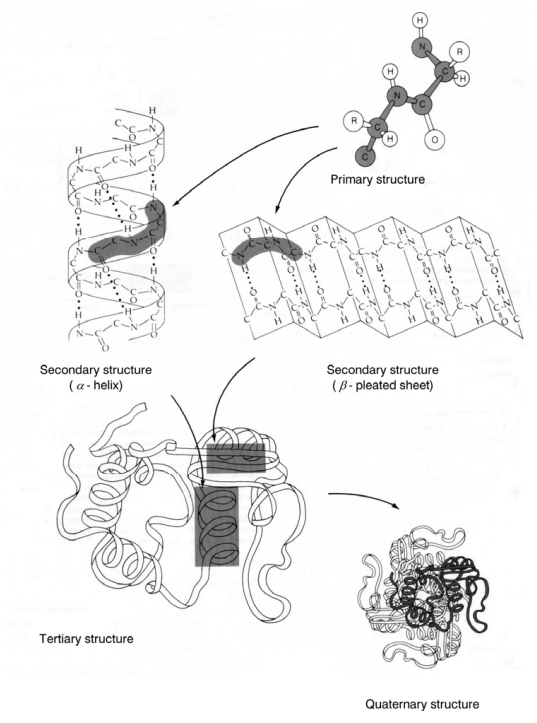
Figure 2–33 A. Schematic presentation of primary, secondary, tertiary and quaternary structure of proteins (From Taiz and Zeiger, 1991).
Figure 2–33 A. Schematic presentation of primary, secondary, tertiary and quaternary structure of proteins (From Taiz and Zeiger, 1991).

Figure 2–31. Binding of the amino acids by peptide bonds and formation of polypeptide chains.
Protein molecules configuration is determined by several levels of
organization. The amino acid sequence in the polypeptide chain with
NH₂-group unengaged at the one end and the COOH-group at the other
is called primary structure (Fig. 2–32).
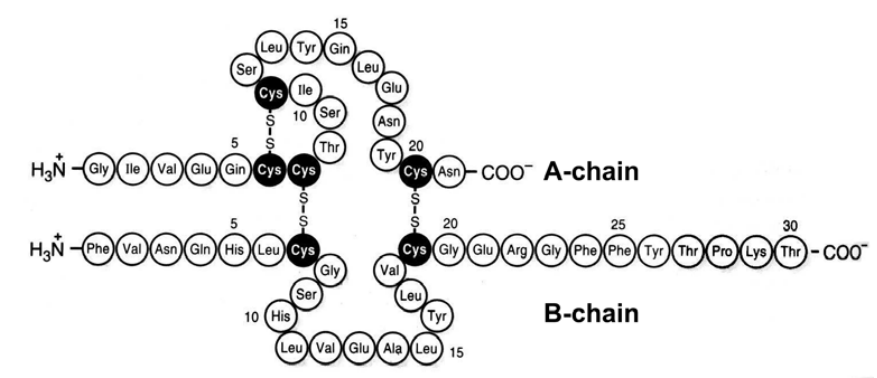
Figure 2–32. Primary structure of human insulin. Disulphide bridges of the native molecule are shown.
Each protein molecule has a spatial configuration as well, determined
by secondary (α-spiral configuration of the polypeptide chains due to the
formation of hydrogen bonds), tertiary (coiling of the chains owing to the
interactions of the amino acid residues inside the chains) and quaternary
(characterized by the formation of bonds between the amino acid residues
from different polypeptide chains) levels of organization determining in their
part its biological activity. These are presented in Figures 2–33 A and B.
image
Figure 2–30. Spiral configuration of the polypeptid chain (After Pauling, 1960).
Structurally, proteins are globular and spiral. Spiral proteins
can be built from one or several polypeptide chains. By X-ray analyses
the structural organization of a great number of protein molecules,
enzymes including has been elucidated — hemoglobin, myoglobin,
myosin, trypsin, ribonuclease, etc. Of special interest are the spiral
configurations of the polypeptide chains and the α-spiral of Pauling
(1960) in particular (Fig. 2–30), having triggered ideas on disclosure
of the spatial structure of DNA. All atoms building the molecule
skeleton have independent orientation. The structure resembles
a spiral staircase in which the “steps” are amino acid residues.
Each residue occupies 1.5 nm of the spiral axis. One coil is equal to
5.3 nm. It is stabilized by hydrogen bonds between the carboxyl group
of one residue with the amino group of the other.
Of the twenty amino acids (see Fig. 2–29) comprising the
various proteins all but one (proline) have a uniform structure

group (—COOH) are bound to the α-carbon atom.
Protein molecules are built from amino acids in a linear sequence
bound to one another by peptide bonds. Peptide bonds result from the
interaction of the α-amino group (—NH₂) of the amino acid with the α-carboxyl
group (—COOH) of the other thus releasing H₂O. The binding of amino
acids leads to the formation of polypeptide chains (Fig. 2–31).
Proteins are subdivided into two major groups:
a) simple proteins (Greek: prótos — primary) composed only of amino
acids. Such are the albumins, globulins, histones, glutamins, prolamins, etc.
Of special interest here are the histones and protamins which take part
into complicated interrelationships with the nucleic acids in the processes of
protein synthesis and transfer of hereditary information in the
chromosomes, that is why they will be mentioned again in the next Section.
image
Figure 2–29. The twenty amino acids which participate in the building of proteins. All of them are L-forms.
b) complex — proteids, incorporating in themselves other components
except amino acids. Such are the glycoproteids (+ carbohydrates),
nucleoproteids (+ nucleic acids), lipoproteids (+ lipids), phosphoproteids
(+ phosphoric acids) and chromoproteids (+ pigments with groups
containing metals).
Section 2.7. In this Section the cell as a generalized notion will be
considered in the light of the chromosome theory and the Watson and Crick
model of DNA, underlying the modern interpretations of its development
and reproduction. Naturally, the results of classical cytology and genetics
will not be ignored, as well as certain deviations from the concepts that
have been imposed for a given period of time as the only correct ones.
If the existing data, opinions and hypotheses about life origins are
fastidiously scrutinized (see Chapter 1) it would not be hard to admit that
the abiotic formation of the monomers by “the lucky combining” of atoms
and molecules in the non-living nature and their conversion under suitable
conditions into biopolymers with the corresponding primitive self-reproductive
mechanisms has given rise to living matter formed initially into
cell structures and only after that into unicellular and multicellular
organisms.
Biopolymers are naturally found compounds of high-molecular weight
consisting of monomers bound by a specific manner into long chains of
strictly defined configuration and biological functions. Since cells represent
in themselves very complex biological systems in their composition, it is
impossible to even make suggestions about their ultimate chemical and
biochemical organization. That is why only the most important biopolymers
will be spelled out — proteins, nucleic acids and carbohydrates, these
being the major cell components.
Proteins
Proteins are high-molecular organic compounds, built from lineary situated
amino acids, with a molecular weight ranging from 1×10⁶
to 1×10¹⁰ daltons.
Out of over the 150 identified amino acids only 20 of them take part in the
composition of protein molecules (Fig. 2–29).
Literature data allow for the possibility of formation of more than 10³²⁰
different proteins with an average length of the chain of about 300 amino acid
residues. Simultaneously it is admitted that such a number of proteins would
have hardly been possible in reality. It is much more likely for their fund to be
much less numerous, the course of evolution eliminating most of them and
only preserving the really needed ones.
Chemical analyses have shown that after water (about 70%) protein
content (more than 50% of the dry matter) comes second as quantity in the
cell composition. Theirs is the biological function to determine the structure,
to keep up growth and take part in the realization of all vital processes
related to their development and division including cell specialization,
differentiation and dedifferentiation which will be further treated in detail.
still no clear and exact definition of the notion of the gene and its real
dimensions. Most probably we shall be encountering the situation with the
atom in chemistry, which only before several decades was considered the
smallest and indivisible unit. There are enough data to think that today’s
notion of the gene is rather different from the real one and in the oncoming
XXI century it will be called “classical”.
In 1935 the well-known physicist and biologist Max Delbrück has
expressed his view in his theoretical report “On the nature of gene mutation
and gene structure” that if in physics all changes can be in principle
reduced to measurements of place and time, the basic notion of genetics —
the difference in feature — can hardly be sensibly expressed in absolute
units (cited by Stent, 1974). Another physicist E. Schrödinger (1945) has
expressed the thought that independently of its chemical nature the gene
should be exceptionally small, no more than several atoms. Otherwise the
great number of genes that are thought to be needed for every organism
could not have been held in the cell nucleus.
The prevalent opinion is that genome organization and its basic
structural and functional unit for heredity — the gene, are inadequately
clarified. This can be considered to be the fourth “white spot” in biology,
genetics respectively. In my opinion it is possible for the genes to prove
undefined strictly genetic structures arranged as “beads” along the DNA
molecule, but biochemical prerequisites derived from the combination of
high-molecular organic compounds (mainly proteins, nucleic acids and
specific enzymes) in different portions of the chromosomes, which as a
result of their interaction in the process of development to form the
hereditary features, qualities and properties of living organisms. Only in
this way can the stunning variety of disappeared and viable species be
explained together with the wide range of overlapping colours of living
nature, as well as the unceasing anomalies which would not have
happened if the genes were in reality strictly defined, programmed and
unchangeable structures.
If this hypothesis is confirmed, then it should be accepted that the
processes of heredity are more biochemical than genetic ones. It is quite
improbable for the genetic information in DNA to be kept in an “academician”
state and not to take part in the life processes, executing only control functions
as postulated by the followers of the Central dogma in biology (see Alberts et
al., 1986). Such a role is not typical of living matter, which is organized and
developed on the basis of real mutual relationships and interactions.
Looking for the causes of the sickle-cell anemia in the human (Fig. 2–28)
Ingram (1956, 1957) has established that it is due to differences in hemoglobin
composition. Normal erythrocytes contain hemoglobin A (HbA) while the
sickle-cell ones contain the pathological hemoglobin (HbS) in which glutamine
in the polypeptide chain is replaced by valine. The presence of HbS leads to
deformation of the erythrocytes, aggregation, thrombus formation and all
syndromes typical of the sickle-cell anemia.
image
image
Figure 2–28. Sickle-cell anemia in man (From Stent, 1974). A — micrograph of erythrocytes from a patient with sickle-cell anemia (at low oxygen pressure); B — micrograph of erythrocytes from a healthy man (under the same conditions).
These are great achievements of molecular biology and genetics. They
show the way for the study of the gene at the molecular level which is
undisputedly the only one possible. It must be noted however, that there is
Such calculations are not only attractive but they are necessary as
well. They create the feeling that the problem of the gene expression at the
cell and organism levels is almost solved. Lots of data however give
grounds to the thought that these are rather hasty and insufficiently
accounted for, since the gene itself proved to be a more complex structure
than expected. To the present day is a question still unanswered: what is a
gene and what are its real dimensions?
It can be definitely stated that there is not a precise and undisputed
definition of the gene, although it underlies the basis of genetics and
molecular biology. As most acceptable is to think that the gene represents
a segment of the chromosome encoding for a functionally active product
(either RNA or the product of its translation — a polypeptide).
The idea of the gene has been changing depending on the level of
knowledge in that field. Let us follow its development in an historical aspect.
Mendel’s experiments binding the inheritance of the features in the
offspring to the hereditary factors bore the term “gene” later on. T. Morgan and
his collaborators have arrived at the conclusion that the gene is an indivisible
structure which is the unit for function, mutation and recombination. N. Dubinin
has launched the idea that the gene can be divided.
If the functions of the genes are judged by the results of their
expression, i.e. by the determination of the hereditary feature, then the
initial definition of classical genetics one gene — one hereditary feature
was rather convincing. When it was established that the gene (cistron) is
divisible into smaller subunit (sites) that can change independently one of
another and mutate at various frequencies (Benzer, 1955—61), two or
more complementary genes can take part in the formation of one and the
same feature (multiple allelism) and only one gene can determine various
features and properties (pleiotropic action of the genes), then its initial
definition proved to be rather limited so that it could meet the more recent
ideas about its structural organization and functions.
The studies of Beadle and Tatum (1941) on the auxotrophic mutants in
Neurospora crasa showed that they are obtained as a result of the
disorders in the synthesis of a given enzyme controlled by a given gene.
This fact gave the authors the grounds to make the generalization one
gene — one enzyme. For the first time the link between genes and
enzymes was established.
Since all enzymes are proteins this definition was modified into “one
gene — one protein”. Based on the achievements of modern molecular
biology and genetics, that most protein molecules are built from several
polypeptide chains whose structure is determined by different genes the up-to-date
formulation of gene expression is one gene — one polypeptide chain.
phenotypic changes (Bridges, 1935—38), and the results from a number of
studies in that trend have created the notion of the disc as an independent
functional unit, i.e. a gene determining a definite hereditary feature or
property of a single cell or organism. Gene maps of the polythene
chromosomes of a number of research objects have been constructed and
in-detail calculations of the gene quantity and the controlled by them features
have been carried out both for the individual chromosomes and the genome
as a whole. So, for example, the genome of Drosophila melanogaster was
initially calculated to be about 10 000 and after that reduced to 5000 genes
encoding the synthesis of 5000 proteins of medium size, consisting of 400
amino acid residues each. Such calculations have been performed for many
other unicellular and multicellular organisms, man including whose genome
was calculated to be 6 million genes corrected to 3 million later.
Gene maps of the loci of different genes have also been made. Studying
the fine structure and topography of a small portion of the chromosome of the
phage T4, Benzer (1961) has established an irregular distribution of the point
mutations along its length (Fig. 2–27). The author has suggested a
nomenclature of his, dividing the chromosomes into cistrons (A, B, etc.) which
correspond to the already firmly established notion of the gene, and the cistrone
was divided into sites. He has also introduced the terms muton (the smallest
unit of mutation) and recon (the smallest unit of recombination).
image
Figure 2–27. Topographic map of the rII region of phage T4 for spontaneous mutations (After Benzer, 1961). Each square corresponds to one mutation event. In most cases they are not established. Different sites, in which the area rII can be divided by means of deletions, are marked by the symbols A1a, A1b1, A1b2, etc. In some sites, so-called “hot spots”, the mutations are much more than in others. Dotted line shows the borders of the cystrons A and B.
This was first reported by A. Marshak and S. Marshak (1955) and was later
confirmed by other researchers (see Studitsky, 1981).
image
image
Figure 2–26. (A) Phase-contrast photograph of axolot bilavent XIII entire in Ambistoma mexicanum (After Callan, 1966). c — centromer; re — right end; s — sphere; sl — stiff loops. (B) Diagrams illustrated what happens when part of a lampbrush chromosome is stretched (After Callan, 1963). (a) unstretched; (b) stretched within the elastic limit; (c) stretched beyond the elastic limit — one chromosome is broken, and a pair of lateral loops span the break.
Both the assumption of the disc invariability in number and their situation
in the polythene chromosomes (Painter, 1933) and correlation with the